Google File System (GFS) is a scalable distributed file system designed for high performance, fault tolerance, and high availability, running on inexpensive commodity hardware. Many distributed systems, such as HDFS, Ceph, and S3, are widely used in the industry today. GFS was one of the first distributed storage systems to be used at a large scale, significantly influencing subsequent designs, particularly HDFS. It incorporates fundamental concepts of distribution, sharding, and fault tolerance, scales effectively, and was built based on Google’s extensive experience with large-scale data processing. GFS successfully implemented a single master architecture and a weak consistency model, which contributed to its high performance and scalability, despite introducing potential trade-offs like single points of failure and weaker consistency guarantees.
Despite the complexity of distributed storage systems, the GFS paper is easy to read. Understanding GFS gives valuable insights into how a basic distributed storage system works and is a great first step in learning about distributed systems.
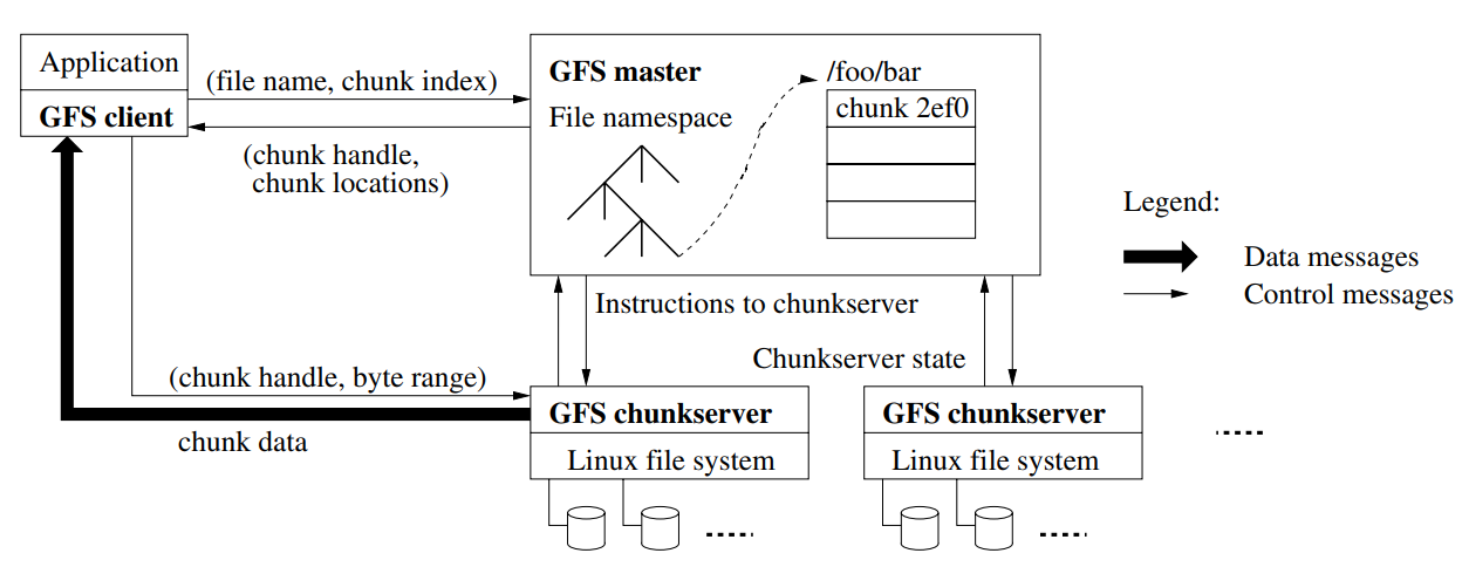
Google File System Architecture
GFS has three major components: Client, Master, and Chunkserver. GFS splits a file into multiple chunks and saves them into Chunkservers. The Master stores metadata in memory, which contains each chunk’s location information. Metadata operations use a Binlog and Checkpoint for backup and crash recovery.
When a client writes a file to GFS, the client first asks the Master about which Chunkserver can store this file. The Master returns the metadata to the client. The client then splits the file into chunks and sends them to the Chunkservers indicated by the metadata.
The read process is similar to the write process. First, the client retrieves the metadata, then reads each chunk from the Chunkservers, and finally combines the chunks to form the complete file.
To understand the entire architecture, you just need to know the relationship among the Client, Master, and Chunkserver.
Consistency Model
Data consistency is crucial in distributed storage systems, as it ensures that all clients have a uniform view of the data. The consistency model of GFS addresses the challenges of maintaining consistent data across multiple nodes.
In a distributed system, the consistency problem is akin to a race condition in an operating system. For instance, if multiple threads access and modify a variable concurrently, they may end up with different values at different times. This issue becomes more complex in a distributed environment where nodes are geographically dispersed.
Consider the following scenario:
A----set x = 1
B----set x = 2
C----get x = ? // in A
C----get x = ? // in B
If nodes A and B set the value of x concurrently, node C may read different values from A and B. To handle such consistency issues, GFS employs a primary-secondary model for chunk replication. The primary chunkserver handles all mutations and coordinates with secondary chunkservers to ensure consistent data replication.
The main challenges addressed by GFS’s consistency model are:
- Guaranteeing the order of writes in different nodes: Synchronizing write order across distributed nodes is challenging due to network latencies and time synchronization issues.
- Ensuring consistent reads across replicas: By reducing write operations to a single primary node and synchronizing replicas, GFS maintains consistency across the system.
To address these challenges, GFS defines specific consistency guarantees that describe the expected behavior of the system under various conditions. These guarantees help to understand how data will be managed and accessed consistently.
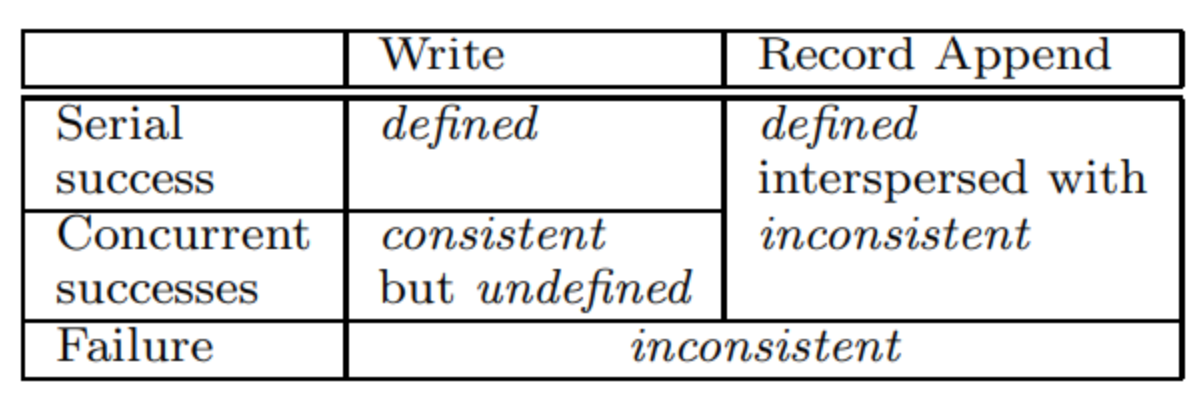
The GFS consistency guarantees are categorized as follows:
- Consistent: All clients will see the same data.
- Defined: After a mutation, clients will see the exact data written by the mutation.
- Undefined: Clients don’t know which mutation has been written, but the data remains consistent.
- Inconsistent: Data is corrupted and cannot be used.
GFS provides these consistency guarantees through its primary-secondary model. The primary chunkserver receives the data first and then replicates it to secondary chunkservers. This mechanism simplifies the consistency problem to a single-node concurrency issue.
Lease Mechanism
The lease mechanism plays a crucial role in maintaining consistency during write operations. The master grants a lease to one of the chunkservers, making it the primary for a specific chunk. The primary chunkserver coordinates all mutations to ensure they are applied in a consistent order.
- Lease Renewal and Expiry:
- The primary chunkserver periodically renews its lease by sending heartbeat messages to the master.
- If the lease expires (e.g., due to a failure of the primary chunkserver), the master can grant a new lease to another chunkserver, which then becomes the new primary.
- Write Coordination:
- When a client wants to write to a chunk, it contacts the master to identify the primary chunkserver.
- The primary chunkserver coordinates the write operation by first applying the write to its local copy and then propagating the changes to the secondary chunkservers in the same order. This ordered replication ensures that all chunkservers have consistent data.
Write and Record Append Operations
GFS supports two types of concurrent writing operations: write and record append.
- Write Operation: When multiple clients perform write operations concurrently, GFS does not guarantee the order of writes. The data written by different clients may be interleaved, resulting in an undefined but consistent state. If a client writes to a chunk, the primary chunkserver ensures the data is replicated to secondary chunkservers in the same order. However, if multiple clients write simultaneously, the order of their writes is not preserved.
- Record Append Operation: Record append operations are designed for applications that need to append data to a file, such as logging. In this operation, GFS ensures that data is appended atomically and consistently. When one client writes to a chunk, the chunk is locked, and subsequent writes are directed to the next chunk. This ensures at least once atomic writes, maintaining consistency across multiple producers.
x=1
x=2
x=3
x=4
The steps for a record append operation are as follows (adapted from MIT 6.824):
- Client C asks Master M about the file’s last chunk.
- If the chunk has no primary or the lease has expired:
- If no chunkservers have the latest version number, an error occurs.
- Pick primary P and secondaries from those with the latest version number.
- Increment the version number and write to the log on disk.
- Notify P and secondaries about their roles and the new version number.
- Replicas write the new version number to disk.
- Master M tells Client C the primary and secondary chunkservers.
- Client C sends data to all (write in cache) and waits.
- Client C tells Primary P to append.
- Primary P checks that the lease hasn’t expired and that the chunk has space.
- Primary P picks an offset (at the end of the chunk) and writes the chunk file.
- Primary P tells each secondary the offset and instructs them to append to the chunk file.
- Primary P waits for all secondaries to reply or time out.
- Primary P tells Client C “ok” or “error”.
- Client C retries from the start if an error occurs.
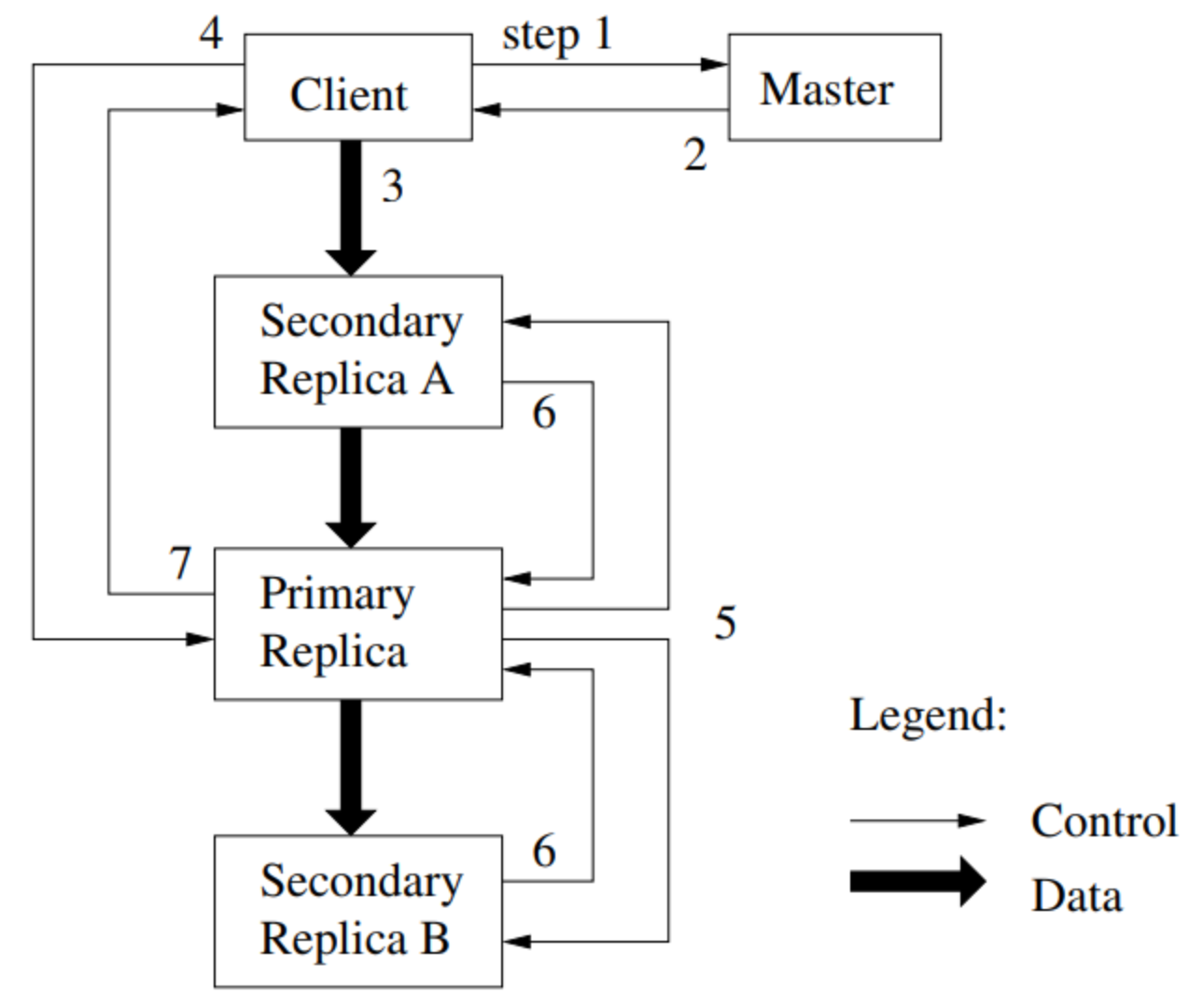
The above steps send data to the primary and then to the secondaries. Data is first cached in memory and then written to disk. This writing process is separated into two steps:
- Data is cached using the LRU (Least Recently Used) mechanism.
- Upon receiving the disk write request, the system starts writing to disk.
The primary holds the lease that determines the data order for the secondaries. This writing mechanism also reduces disk I/O pressure.
How about the normal write? It’s the same as the record append. The primary chunkserver and two secondaries must write in the same order. When two concurrent clients write data, the order of writing is not guaranteed, which is called ‘undefined’ in GFS. However, the data will be written consistently on different nodes (undefined but consistent).
If one of the three chunks fails to write, how is it handled? Rewrite the three replicas to another chunk. The old three chunks will be reclaimed by the garbage collection scanner.
The steps for client C to read a file (adapted from MIT 6.824):
- Client C sends the filename and offset to Master M (if not cached).
- Master M finds the chunk handle for that offset.
- Master M replies with a list of chunkservers that have the latest version.
- Client C caches the handle and chunkserver list.
- Client C sends a request to the nearest chunkserver with the chunk handle and offset.
- The chunkserver reads from the chunk file on disk and returns the data.
How Does GFS Maintain High Availability?
GFS is designed to ensure high availability, minimizing downtime and ensuring continuous access to data even in the face of hardware failures. This is achieved through several key mechanisms:
Chunk Replication
Each file in GFS is divided into fixed-size chunks, typically 64 MB each, and each chunk is replicated across multiple chunkservers (usually three) to ensure redundancy. This replication ensures that if one chunkserver fails, the data is still available from other chunkservers.
Handling Chunkserver Failures
When a chunkserver fails, the system detects the failure through missed heartbeats. The master then re-replicates the lost chunks to other chunkservers to restore the replication level. This re-replication is done by copying the chunks from the remaining replicas to new chunkservers. The master keeps track of the chunk versions to avoid stale replicas.
Handling Master Failures
The master is a single point of failure in GFS. To mitigate this, the master’s state is periodically checkpointed, and updates are logged. In the event of a master failure, a new master can be started, which reads the checkpoint and log to restore the system state. Additionally, GFS can use shadow masters, which provide read-only access to the metadata, ensuring that read operations can continue even if the primary master is down.
Steps for maintaining high availability
1. Chunk Replication:
- Files are split into chunks and each chunk is replicated across multiple chunkservers.
- Replicas are placed on different racks to ensure availability even in case of a rack failure.
2. Detection and Handling of Chunkserver Failures:
- The master regularly sends heartbeats to chunkservers.
- If a chunkserver fails to respond, it is marked as dead.
- The master re-replicates the data from the failed chunkserver to other chunkservers.
3. Master Recovery:
- The master’s state is checkpointed and logged.
- In case of a master failure, a new master is started, which loads the last checkpoint and replay logs.
- Shadow masters provide read-only access to metadata during master recovery.
Garbage Collection in GFS
Garbage collection in GFS is essential for efficiently managing storage space by removing files and chunks that are no longer needed. This process ensures that the system remains organized and does not waste resources.
File Deletion
When a file is deleted in GFS, it is not immediately removed. Instead, it is marked for deletion and renamed to a hidden file. This delayed deletion approach provides several benefits:
- Safety: Allows recovery from accidental deletions.
- Robustness: Ensures the system can handle failures during the deletion process without losing important data.
The master keeps track of these hidden files and their metadata, indicating that they are scheduled for deletion.
Orphaned Chunks
Orphaned chunks are chunks that no longer have any references from any file. These can occur when files that reference these chunks are deleted. The master periodically scans the metadata to identify such chunks.
Garbage Collection Process
The garbage collection process in GFS operates in the background to reclaim storage space efficiently. It involves three main steps:
1. Identifying Orphaned Chunks:
- The master server periodically scans the metadata to find chunks that are no longer referenced by any file. This includes chunks from files that have been marked for deletion.
2. Deleting Orphaned Chunks and Files Marked for Deletion:
- Once orphaned chunks are identified, the master server instructs the chunkservers to delete these chunks.
- The master also manages the deletion of hidden files that were previously marked for deletion. These hidden files and their associated chunks are permanently removed.
3. Gradual Deletion:
- The deletion process is done gradually to avoid impacting system performance.
By running the garbage collection process during times of low system activity, GFS ensures that it does not interfere with normal operations. This process helps maintain the overall health and efficiency of the storage system.
Other Questions
To better understand GFS, I copied some questions from the MIT 6.824 lecture and attempted to answer them.
Why Big Chunks?
Google has many large files that need to be stored. Splitting files into big chunks can reduce I/O pressure and the size of metadata, improving overall system performance.
Why a Log and Checkpoint?
The single master has to save the metadata safely. A binlog is a simple way to save the metadata safely. Using a checkpoint can restore a crashed master instantly.
How Does the Master Know Which Chunkservers Have a Given Chunk?
A chunkserver reports its chunk information to the master when it starts and sends a heartbeat package to the master.
What If an Appending Client Fails at an Awkward Moment? Is There an Awkward Moment?
There is no need for much concern; simply append it again.
c1 c2 c3
a a a
b b b
c c x // broken written
d d d
c c c // append again
What If the Appending Client Has Cached a Stale (Wrong) Primary?
It should wait for the lease time to expire for the stale primary or request the master again.
What If the Reading Client Has Cached a Stale Secondary List?
The stale secondary will return stale chunks, but the client can detect this.
Could a Master Crash and Reboot Cause It to Forget About the File? Or Forget Which Chunkservers Hold the Relevant Chunk?
When the master restarts, it will restore the state from the binlog, and the connected chunkservers will report their chunk information.
Two Clients Do Record Append at Exactly the Same Time. Will They Overwrite Each Other’s Records?
No, they will not. Because the record append has an “at least once atomic” mechanism.
Suppose One Secondary Never Hears the Append Command from the Primary. What If a Reading Client Reads from That Secondary?
The client would never read from this secondary because no data has been written successfully.
What If the Primary Crashes Before Sending Append to All Secondaries? Could a Secondary That Didn’t See the Append Be Chosen as the New Primary?
Yes. According to the appending process, the data is written to memory first and then to disk. If the primary crashes, the data will be removed from memory.
Chunkserver S4 with an Old Stale Copy of a Chunk Is Offline. The Primary and All Live Secondaries Crash. S4 Comes Back to Life (Before the Primary and Secondaries). Will the Master Choose S4 (with the Stale Chunk) as the Primary? Is It Better to Have a Primary with Stale Data, or No Replicas at All?
Yes, S4 would be chosen as the primary. But its stale data will be scanned by the master. After the old primary is restarted, the stale chunk can be rewritten from other replicas.
What Should a Primary Do If a Secondary Always Fails Writes? e.g., Dead, Out of Disk Space, or Disk Has Broken. Should the Primary Drop the Secondary from the Set of Secondaries and Then Return Success to Client Appends? Or Should the Primary Keep Sending Ops, Having Them Fail, and Thus Fail Every Client Write Request?
The primary would keep sending ops, and clients would choose another set to write. If a new server or disk has been chosen in the set, it will trigger the re-replica for rebalancing chunks.
What If Primary S1 Is Alive and Serving Client Requests, but the Network Between the Master and S1 Fails (Network Partition)? Will the Master Pick a New Primary? Will There Now Be Two Primaries, So That the Append Goes to One Primary and the Read to the Other, Thus Breaking the Consistency Guarantee (Split Brain)?
No, it doesn’t break the consistency guarantee. The primary must serve for the lease time. After this time, a new primary would be chosen.
If There’s a Partitioned Primary Serving Client Appends, and Its Lease Expires, and the Master Picks a New Primary, Will the New Primary Have the Latest Data as Updated by the Partitioned Primary?
Yes, it will have the latest data that was updated by the old primary because the lease can guarantee data consistency.
What If the Master Fails Altogether? Will the Replacement Know Everything the Dead Master Knew? e.g., Each Chunk’s Version Number, Primary, Lease Expiry Time?
The replacement should restore the information that the dead master knew, and the lease should still wait for the exact time for expiring.
Who/What Decides the Master Is Dead and Must Be Replaced? Could the Master Replicas Ping the Master and Take Over If There Is No Response?
The monitor decides if the master is dead or not. It takes over the dead master, restarts the master, or switches to a shadow master (read-only).
What Happens If the Entire Building Suffers a Power Failure? And Then Power Is Restored, and All Servers Reboot.
The master will restore its metadata, reconnect to chunkservers, and reconstruct the entire system.
Is There Any Circumstance in Which GFS Will Break the Guarantee?
As answered by the teacher:
- All master replicas permanently lose state (permanent disk failure). The result will be “no answer,” not “incorrect data” (fail-stop).
- All chunkservers holding the chunk permanently lose disk content. Again, fail-stop; not the worst possible outcome.
- CPU, RAM, network, or disk yields an incorrect value. Checksum catches some cases, but not all.
- Time is not properly synchronized, so leases don’t work out. This could lead to multiple primaries, where a write goes to one, and a read goes to another.
What Application-Visible Anomalous Behavior Does GFS Allow? Will All Clients See the Same File Content? Could One Client See a Record That Another Client Doesn’t See at All? Will a Client See the Same Content If It Reads a File Twice? Will All Clients See Successfully Appended Records in the Same Order?
GFS is a weakly consistent system; writing may result in inconsistent data. If clients read the inconsistent data, the library code would help them check for inconsistencies. According to the GFS consistency model, all clients should see the same content at different times. Inconsistent data should never be returned to the applications.
Will These Anomalies Cause Trouble for Applications? How About MapReduce?
Inconsistent data is worse and completely unusable, causing trouble for applications.
Conclusion
I hope this article has given you a better understanding of how the Google File System (GFS) works as a scalable distributed file system, including its architecture, consistency model, high availability mechanisms, and garbage collection process. If you have any questions or comments, please feel free to leave a comment below.
References
Note: This post was originally published on liyafu.com (One of our makers' personal blog)
Nowadays, we spend most of my time building softwares. This means less time writing. Building softwares has become my default way of online expression. Currently, we are working on Slippod, a privacy-first desktop note-taking app and TextPixie, a tool to transform text including translation and extraction.